Prírodou inšpirované algoritmy
študijné materiály pre projekt mobilnej triedy umelej inteligencie
|
|||||||||||||||||||||

Algoritmus GARP
Indukcia pravidiel použitím genetického algoritmu (GARP)
Algoritmus GARP bol vytvorený Davidom Stockwellom z ERIN Unit of Environment v Austrálii a v pôvodnom návrhu je súčasťou komplexného modelovacieho systému GMS (GARP modelling system), ktorý okrem samotnej predikcie vykonáva predspracovanie, inicializáciu dát ako aj formátovanie výstupu. GMS sa skladá z ôsmich modulov, ktoré sú navrhnuté ako komponenty v systéme kaskádneho spracovania dát . To znamená, že jednotlivé moduly majú presne definované rozhranie a je teda možné ich ľahko doplniť popr. rozšíriť novými prvkami.
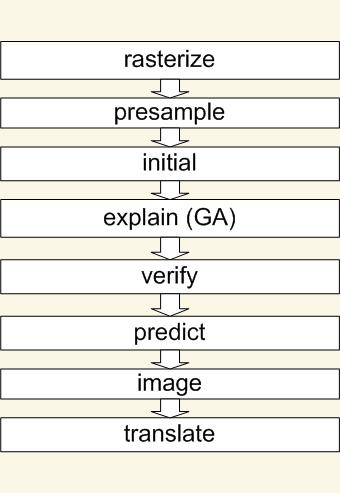
GMS
- rasterize - konvertuje bodové dáta na priestorový ráster dátových vrstiev (layers)
- presample - zjednocuje dáta na uniformnú veľkosť, normalizuje pravdepodobnosti a pokrytie. Vytvára trénovaciu a testovaciu množinu.
- initial - vytvára základný (prvý) model, inicializuje model
- explain - aplikuje genetický algoritmus na tento model, jeho výstupom je množina najlepších modelov
- verify - vyhodnocuje modely z predchádzajúceho výstupu
- predict - aplikuje model na vstupné dáta
- image - vytvára obrázok na základe predikčných dát
- translate - poskytuje vysvetlenie (interpretáciu nájdeného modelu)
Dátové formáty a predspracovanie.
Predspracovanie pozostáva z transformácie geografických dát na sériu vrstiev (layers) a ich rozdelenie do trénovacej a testovacej množiny. Úlohou biologického modelovania je spracovať jednotlivé lokálne dáta výskytu daného druhu a na ich základe vytvoriť čo možno najpresnejšiu mapu potenciálnej distribúcie. Dáta z jednotlivych lokalít (tzv.lokálne dáta) sú zväčša sériou bodov ( daných geogragfickou polohou) kde sa daný druh vyskytuje resp. nevyskytuje.
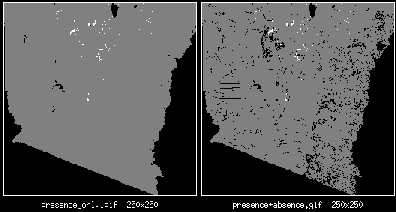
Dátový súbor taktiež nazývaný bodové pokrytie (point coverage popr. geocoded flat file) je ASCII súbor kde prvé dva stĺpce sú geografické dáta ( stupeň zemepisnej širky a dľžky) a ďalšie sú početnosť výskytu daného druhu popr. hodnoty parametrov napr.:
150.775 -35.005 0 0 1178 195 169 0148.005 -35.005 1 3 824 204 138 5
...
Zdrojom týchto dát sú zväčša databázy a GIS aplikácie (geographical information systems). Ďalším súborom je súbor parametrov, ktorý úchováva informáciu o jednotlivých premenných ( min, max hodnotu, typ, jednotky, formát).
Modul rasterize použije ako vstup parametrický a dátový súbor a vytvorí sériu vrstiev (obrázkov). V danom obrázku množina bodov (1 bod = 1 byte) reprezentuje svojím umiestnením nejaké geografické miesto a svojou hodnotou výskyt druhu popr. hodnotu parametra. Keďže hodnota môže nadobúdať hodnoty v rozmedzi 0 až 255 je nutné všetky dáta normalizovať do tohoto intervalu. Pre výskyt daného druhu bod nadobúda hodnotu ak pre dané miesto existuje jeden alebo viacero výskytov, pri spojitých a reálnych dátach bod nadobúda normalizovanú strednú hodnotu. Príklad jednotlivých vrstiev je možné vidieť na obrazku ( výstup modulu rasterize)
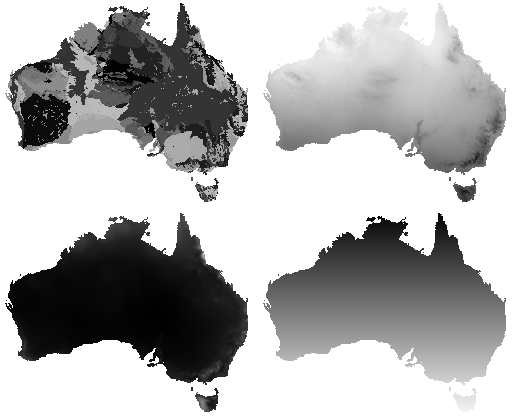
Reprezentácia a vhodnosť.
Modul presample vytvára trénovaciu a testovaciu množinu. Trénovacia množina je použitá na indukciu modelu, testovacia na overenie kvality nájdeného modelu. Do modulu je možné zahrnúť aj náhradu, čo sa využíva hlavne v prípade nedostaku dát popr. pri takmer vyhynutých druhoch kedy počet výskytov je veľmi nízky. Modul initial vytvára prvý model, ktorý je vlastne len množinou pravidiel, ktorá sa nasledné spracuje genetickým algoritmom. Každé pravidlo je pravidlom typu ak-potom (if-then), logika predikcie pri pravidle je :
Pre pravidlo
Presnosť pravidla je daná pravdepodobnosťou. Keďže predpoklad ohraničuje vstupný priestor, pravdepodobnosť je potom možné vyrátať ako podiel výskytu jedinca v tomto subpriestore k veľkosti daného subpriestoru. Príklad výstupu modulu initial je:
1 r 169 189 0 255 0 255 0 255 173 255 248 255 0 255 0 255 0.000 0.000
0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0 1 0 r 0 16
1 m 169 255 127 254 1 254 152 254 85 254 85 254 1 127 254 254 0.000
0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0 1 0 r 0 16
1 d 169 189 0 255 1 254 152 254 85 254 0 255 1 127 0 255 0.000 0.000
0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0 1 0 r 0 16
1 a 169 189 124 124 1 1 203 203 0 255 0 255 0 255 0 255 0.000 0.000
0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0 1 0 r 0 16
...
Prvý stĺpec obsahuje inidikátor použitia/nepoužitia daného pravidla. Ďalej je uvedený typ pravidla (r - logistic, m - bioclim, d - range, a - atomic viď. ďalej), hodnota prvej premennej (závislej), minimum parametra alebo hodnota ( v závislosti na type pravidla), maximum parametra atď. Závislá premenná môźe byť vyjadrená dvoma hodnotami, ak typ pravidla je d alebo m potom ide o minimum, maximum. Ak typ pravidla je r potom prvá hodnota je koeficient, druhá je irelevantná, ak typ pravidla je a potom prvá hodnota je presnou hodnotou a druhá je irelevantná. V prípade, že rozmedzie hodnôt je 0 255 potom pravidlo je splnené pre všetky hodnoty parametra.
Následne je uvedených desať hodnotiacich parametrov pre dané pravidlo:
- Vhodnosť (signifikancia)
-
Primárna sila =
pXs/n. Určuje pre akú časť subpriestoru je možné aplikovať toto pravidlo. -
Primárna pravdepodobnosť =
pYs/n. Určije akú časť ma predikovaná trieda v trénovacej množine. -
Primárna vzdialenosť =
pYcs/n -
Sekundárna (posteriórna) sila =
pXSs/no -
Sekundárna pravdepodobnosť =
pXYs/no -
Sekundárna vzdialenosť =
pYcXs/no -
Pokrytie =
no/n -
Signifikancia =
(pXYs-no*pYs/n)/sqrt(no*pYs*(1-pYs/n)/n) -
Chyba = Signifikancia * sqrt (( pXYs/no)*(1-pXYs/no))/no
pričom:
- pXs - aplikačný potenciál pravidla (sila). Ak daný bod splňuje predpoklad je rovný 1, ak nie 0
- pYs - určitosť pravidla. Ak predikovaná hodnota splňuje následok pravidla potom 1, inak 0
- no - počet bodov selektovaných predpokladom
- pXSs - suma pXs po aplikácii pravidla
- pXYs - suma pYs po aplikácii pravidla
posledných šesť hodnôt sú :
- počet generácií
- indikátor, či pravidlo už bolo vyhodnotené
- koľkokrát bolo pravidlo vyhodnotené
- heuristická hodnota
- monitorovacia hodnota
- dĺžka pravidla
Jednou z výhod GMS je schopnosť pracovať s viacerými pravidlami a tým schopnosť lepšieho popisu daného modelu. V súčasnosti sa používajú štyri typy pravidiel a to : atomické (atomic), BIOCLIM pravidlá, logit pravidlá (Logit) a range pravidlá. Atomické pravidlá maju formu :
IF TANN=23 degC AND GEO=4
THEN PRESENT
patria k najjednoduchším pravidlám, v predpokladovej časti majú len jednu hodnotu pre každý parameter. BIOCLIM pravidlá sú založené na pravidlách použitých v programe BIOCLIM. Pravidlá sa vytvarajú na základe obálky (envelope, súboru podmienok pre parametre), tak aby predpokladová časť vypĺňala aspoň 95% priestoru v ktorom sa daný druh vyskytuje. V GMS sa tieto pravidlá vypočítajú štatisticky. Príklad takéhoto pravidla je:
IF TANN=(23,29]degC AND TMNCM=(10,16]degC AND
TMXWM=(35,38]degC AND TSPAN=(19,27]degC AND
TCLQ=(21,23]degC AND TWMQ=(29,30]degC AND
TWETQ=(24,32]degC AND TDRYQ=(19,26]degC AND
RANN=(609,1420]mm AND RWETM=(156,319]mm AND
RDRY=(1,1]mm AND RCV=(101,123]mm2 AND
RWETQ=(460,874]mm AND RDRYQ=(0,9]mm AND
RCLQ=(1,16]mm AND RWMQ=(272,532]mm
THEN SP=PRESENT
Na rozdiel od atomických predpokladová časť obsahuje rozsahy hodnôt parametrov ( použiva sa symbolika množín, otvorená, uzavretá množina ). Pravidlo môže predikovať buď výskyt alebo absenciu druhu. Range pravidlá sú zovšeobecnené BIOCLIM pravidlá. Počet parametrov je irelevantný, neuvedené parametre môžu nadobúdať ľubovolné hodnoty. Príkladom takéhoto pravidla môže byť pravidlo:
IF GEO=(6,244]c AND TMNEL=(285,1480]masl
THEN SP=ABSENT
Tento typ pravidiel je užitočný keď druhy sa správajú na základe tolerancie a limít voči prostrediu. Logit pravidlá sú adaptáciou logistických regresných pravidiel. Logistická regresia je regresná rovnica v ktorej výstup je transformovaný na pravdepodobnosť ( p = 1/(exp(-y)+1, kde y je predpokladová časť). Napr:
IF 0.1 - GEO*0.1 + TMNEL*0.3
THEN SP=ABSENT
Genetický algoritmus.
GMS používa trochu modifikovaný genetický algoritmus. Reprezentácia jedinca je ekvivalentná reprezentácii pravidla. Jedna iterácia GMS pozostáva z týchto krokov:
- štart, čas t
- inicializuj populáciu P(t)
- náhrada
- vypočítaj hodnotiacu funkciu (fitness) populácie
- umiestni najlepších a vynimočných jedincov do archívu
- testuj podmienku ukončenia
- vyber novú populáciu z archívu
- aplikuj operátory (crossover, mutácia, join)
- t = t + 1
- skok na 3
Archív je vytváraný za účelom vyhnutia sa konvergencie k jednomu pravidlu. Algoritmus začína inicializáciou (2) t.j. načítaním pravidiel vytvorených modulom initial. V ďalšom kroku je vybraná náhodná subpopulácia jedincov (3) a vypočíta sa ich fitness (4), čo je akákoľvek funkcia (utility) zadaná uživateľom resp. signifikancia. Následne sú najlepší a vynimočný jedinci presunutí do archívu (5) a testuje sa stop pravidlo. Stop pravidlo je zisťované na základe zmeny jedincov v archíve, v prípade, že sa nezmenilo viac ako 5 pravidiel zo 100 algoritmus končí. Operátory použité v 8. kroku sú:
- join ( zlúčenie predpokladov dvoch pravidiel),
- mutácia - náhodná zmena hodnoty parametra, buď v rozmedzí 1-254 (random mutation) alebo inkrementáciou (incremental mutation)
- crossover - výmena časti dvoch pravidiel v náhodnom bode
GMS taktiež vyratáva úspešnosť použitia daného operátora a na jej základe mení pravdepodobnosť aplikácie operátora. Signifikancia je použitá ako hodnotiaca funkcia ale je možné aplikovať bias ako napr. sekundárna pravdepodobnosť, selekčný tlak, ekologický priestor ( čo najväčšie pokrytie predpokladom), negácia dĺžky pravidla. Ten je potom použitý pri vyberaní jedincov z archívu.
Modul verify testuje presnosť predikcie vzniknutého modelu na testovacej množine. Výstupom je kontingečná tabuľka, napr. :
VERIFY - predictive accuracy of rules using
training data
Results by value:
BV Value Prop. Acc. Error(S.D.)
0 1 0.04 0.93 0.06
1 85 0.37 0.82 0.03
2 169 0.33 0.23 0.04
3 254 0.27 0.65 0.05
Predicted 1.000
Accuracy 0.585 s.d. 0.025
Overall Acc. 0.585 s.d. 0.025
Modul predict aplikuje odtestovaný predikčný model na vrstvy (layers), pričom hodnota predikcie môže nadobúdať 256 hodnôt. Vzhľadom k tomu, že množstvo dát z tohoto modulu je veľkosť danej vrstvy * 256 (* počet vrstiev) najednoduchším spôsobom prezentácie sú obrázky (raw, miff, bmp, grid, pnm,mesh). Modul translate zjednodušuje množinu pravidiel tak, že vynecháva z predpokladovej časti parametre ktoré môžu nadobúdať ľubovolné hodnoty. Týmto prístupom je výsledok ľahšie zrozumiteľný a jednoduchšie interpretovateľný.