Prírodou inšpirované algoritmy
študijné materiály pre projekt mobilnej triedy umelej inteligencie

Úvod
Simulácia a vizualizácia ekosystémov rastlín má mnoho teoretických a praktických využití. Napríklad zahŕňa základné výskumy v oblasti ekológie. Základná zložitosť prostredí vychádzajúcich zo simulácií ekosystémov, môže byť spracovaná využitím viac–úrovňového prístupu k modelovaniu. Radšej ako model celého ekosystému orgánov rastlín na detailnej úrovni, ako sú listy, kvety, stonky a časti medzi dvoma listami, na modelovanie hierarchie ekosystému použijeme viac–úrovňový model. Napríklad v najjednoduchšom dvoj–úrovňovom prípade vyššia úroveň určuje rozdelenie rastlín a nižšia úroveň určuje tvary rastlín (plants’ shapes). Modely sú prepojené, aby informácie vytvorené na vyššej úrovni mohli ovplyvniť výsledok modelu na nižšej úrovni. Prístup local–to–global je charakteristický tým, že hustota rozdelenia rastlín v tomto modely je určená simuláciou vzájomného pôsobenia jednotlivých rastlín na rozdiel od global–to–local, kde pozície jednotlivých rastlín sú odvodené od rozsiahlej hustoty rozdelenia.
Hlavnou myšlienkou je chápať generovanie ekosystémov rastlín ako postupnosť úloh: presne stanovenie terénu, generovanie rozdelenia rastlín použitím hrubých modelov rastlín, zlúčenie detailných modelov rastlín a vytvorenie finálneho prostredia(scény) použitím ilustrácií detailných modelov. Pri vytváraní rozloženia rastlín sa používajú dve rôzne metódy.
Prvá metóda je založená na individuálnom modelovaní ekosystému, založená na modeli Firbank a Watkinson. Pri použití tohto modelu rastliny sú umiestňované do poľa náhodne a opakovane rastú a zanikajú, ak boli ovládnuté väčšou rastlinou. Tento model sa využíval hlavne na určenie rozloženia rastlín podľa veľkosti, podobné môžeme sledovať v prírode.
Druhá metóda umožňuje viacerým užívateľom definovať lokálnu hustotu rastlín. Vstupom je čiernobiely obrázok reprezentujúci mapu hustoty rastlín v rámci jedného poľa. Na určenie pozície jednotlivých rastlín sa využíval Floyd–Steinberg–ov algoritmus chyby rozširovania. Tieto metódy majú tendenciu vytvárať modely nemeniaceho sa rozdelenia rastlín. Čo sa ale odlišuje od reality. V skutočnosti, sa rastliny rovnakého typu často zoskupujú do chumáčov(clustering) a tiež sa šíria a rozmnožujú šírením semienok, napríklad vetrom alebo nejakými živočíchmi. To má veľký vplyv na výsledné rozdelenie hustoty rastlín, a preto sa snažíme hľadať modely aj pre tieto mechanizmy. Efekt zlučovania sa do chumáčov(clustering) je vyjadrený pomocou Hopkins-ovho indexu H, ktorý je definovaný ako priemerná vzdialenosť od náhodne vybraného bodu k jeho najbližšej rastline v rámci jedného regiónu, rozdeleného pomocou priemernej vzdialenosti od náhodne vybranej rastliny k jej najbližšej rastline:
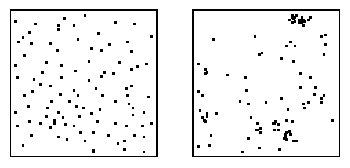
Rozdelenie, ktoré je úplne náhodné ma hodnotu indexu H rovnú 1. Rozdelenie, ktoré je viac rozhádzané ako náhodné (pravidelné), má hodnotu H menšiu ako 1, a rozdelenie, v ktorom sa rastliny zlučujú do chumáčov má hodnotu Hopkins-ovho indexu väčšiu ako 1. Napríklad obrázok dole porovnáva rozdelenie s Hopkins-ovým indexom H=0.4 a rozdelenie zlučujúce sa do chumáčov s indexom H=2.4.