Prírodou inšpirované algoritmy
študijné materiály pre projekt mobilnej triedy umelej inteligencie

Experiment L. Adlemana
Matematika ako vedná disciplína prenikla do mnohých vedných odborov a v rámci nich prispela k jasnej formulácii problémov a mnohokrát aj k ich elegantnému riešeniu. Výnimkou nie je ani biológia. L. Adleman však túto situáciu obrátil naruby. Využil biologické procesy na simuláciu matematických výpočtov. Podstata jeho prístupu je v kódovaní informácie na reťazcoch DNK a vo využití enzýmov na simuláciu jednoduchých výpočtov.
L. Adleman sa podujal prakticky ukázať použitežnosť svojej teórie na testovaní existencie hamiltonovskej cesty v orientovanom grafe. Problém existencie hamiltonovskej cesty v orientovaných grafoch je NP-úplný. Znamená to, že dosiaľ nebol nájdený (mnoho informatikov verí, že ani nikdy nebude nájdený) algoritmus, ktorý by pre ľubovoľný orientovaný graf G a pre jeho ľubovoľné dva vrcholy A, B, po N krokoch rozhodol, či v G existuje cesta z A do B, pričom každý vrchol grafu G by bol navštívený práve raz. Overovanie existencie hamiltonovskej cesty v orientovanom grafe je vo všeobecnosti výpočtovo náročná úloha. Počet potrebných krokov na vyriešenie problému rastie exponenciálne s veľkosťou grafu. Treba však povedať, že NP-úplné problémy robia starosti informatikom len pri úlohách väčšieho rozsahu a L. Adleman si pre svoj experiment zvolil pomerne jednoduchý graf (úlohou je nájsť DNK výpočtami hamiltonovskú cestu z uzla 0 do uzla 6.).
Uveďme si najprv hrubý náčrt algoritmu overujúceho existenciu hamiltonovskej cesty z uzla A do uzla B v orientovanom grafe G s n vrcholmi.
- generuj náhodné cesty v grafe G
- ponechaj si len cesty vychádzajúce z uzla A a končiace v uzle B
- vylúč všetky cesty ktorých dĺžka je rôzna od n
- ponechaj si len cesty, ktoré navštívia každý vrchol najviac raz
- ak je množina zostávajúcich ciest neprázdna, daj kladnú odpoveď, ináč odpovedz záporne.
Teraz si popíšeme ako sa problém hamiltonovskej cesty v orientovanom grafe dá riešiť pomocou molekúl DNK a operácii s nimi.
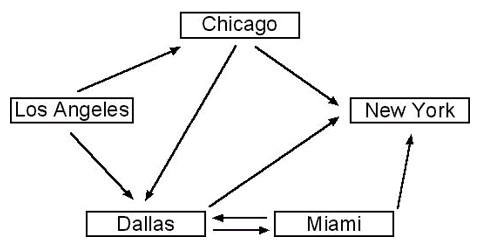
Nech je problém zadaný nasledovným grafom a naším štartujúcim vrcholom je Los Angeles a cieľovým vrcholom New York. Našou úlohou bude nájsť cestu, ktorá začína v Los Angeles a končí v New York-u.
Algoritmus riešenia s použitím DNK bude realizovaný nalsedovne:
-
Vytvorí sa jedinečná DNK sekvencia pre každé mesto (v nasledujúcej tabuľke je kódovanie vrcholov).

-
Pre každú cestu z mesta X do mesta Y vytvorí sa prepojujúca sekvenciu DNK, ktorá reprezentuje cestu z mesta X do mesta Y. Táto cesta je komplemantárna pre poslednú polovicu DNK kódu mesta X a pre prvú polovicu DNK kódu mesta Y. NAsledujúci obrázok ilustruje spôsob ako budeme kódovať cestu medzi mestami.
Na nasledujúcom obrázku je príklad niektorých možných kombinácií ciest
-
Je náročné separovať konkrétnu DNK z výsledku dosiahnutého v kroku 1. Preto bude cieľová DNK, ktorá začína v meste Los Angeles a končí v meste New York viacnásobne kopírovaná. Dosiahneme tak stav, keď skúmavka bude obsahovať veľa správnych a relatívne málo nesprávnych reťazcov. Je to podobný prípad, ako keď do zásuvky s jednou, alebo dvoma farebnými ponožkami pridáme sto čiernych. Je takmer isté, že ak potom náhodne vyberieme jedny, budú čierne. DNK kopírujeme pomocou enzýmu nazývaného polymeráza, ktorý nám umožňuje replikovať prednostne tie reťazce DNK ktoré začínajú a končia nami požadovanou sekvenciou.
-
Potom, podľa váhy molekúl DNK, separujeme od zvyšku tie reťazce DNA, ktoré kódujú cestu cez práve 5 vrcholov. Je použitá priestorová mriežková štruktúra na to, aby menšie reťazce DNK prešli rýchlejšie, kým väčšie sú štruktúrou spomaľované. Táto procedúra nám umožní izolovať častice s dĺžkou ktorá kóduje cestu cez 5 miest od kratších a dlhších ciest.
Použitá metóda sa volá gélová elektroforéza a je založená na tom, že DNK pretláčame cez gélovú maticu pomocou elektrického poľa. DNK molekula má negatívny elektrický potenciál. Bude teda priťahovaná kladným pólom elektrického poľa. Separovanie DNK podľa dĺžky reťazca dosiahneme na základe toho, že štruktúra gélovej matice spomaľuje pohyb DNK molekúl v závislosti na ich veľkosti. Po určitom čase budú molekuly DNK separované v rôznej časti matice na základe veľkosti reťazca DNK. Znázorňuje to nasledujúci obrázok (Jednotka bp znamená bázový pár).
-
Na to, aby nám ostali len reťazce, ktoré obsahujú všetky mestá, použijeme postup nazývaný afinná purifikácia. Využijeme magnetickú guličku, ktorá postupne „podrží“ reťazce DNK, ktoré obsahujú sekvencie DNK kódujúce jednotlivé vrcholy grafu. Deje sa tak na základe komplementu naviazaného na túto magnetickú guličku. Najpr teda "podržíme" reťazce obsahujúce sekvenciu DNK pre New York. Ostatné reťazce DNK sú odstraňované. Zbavíme sa tak reťazcov, ktoré neobsahujú sekvenciu DNK kódujúcu New York. Postup opakujeme pre každé jedno mesto (presnejšie sekvenciu DNK, ktorá ho kóduje). Nakoniec nám ostanú len sekvencie DNK, ktoré majú v sebe zakódované všetky vrcholy grafu. Tento princíp je vyjadrený nasledujúcim obrázkom.
- Ostávajúce reťazce DNK kódujú hľadanú cestu.